
Kedro is a python data science library that helps with:
creating reproducible, maintainable and modular data science code
It does quite a lot so I was keen to try it out.
To do that I created a project to analyse some NBA data. The aim is to download some data from basketball-reference, clean it up, build some models and then plot some results.
Link to the full project repo: https://github.com/stanton119/nba-analysis
Kedro creates pipelines, so we can use those tools to help here. I built two - the data collection and cleaning was written into a data engineering pipeline, and the model fitting and plotting was built into a data science pipeline.
The pipelines are simple to construct with little boilerplate required. E.g. to setup a single node pipeline we reference the function, the input and output datasets and give the node a name:
Pipeline(
[
node(
func=nodes.process_season_data,
inputs=[f"season_data_{season}" for season in season_range],
outputs="cleaned_season_data",
name="process_season_data_node",
),
]
)
One feature which was very handy was the data catalogue. This idea abstracts away all the saving/loading from the pipeline steps. The various files saved to disk are configured using the data catalogue. For example to save a pipeline node output to a parquet file using Pandas, and track the versions of this file:
cleaned_season_data:
type: pandas.ParquetDataSet
filepath: data/02_intermediate/seasons.parquet
layer: intermediate
versioned: true
We can easily change the filepath and the file format without any code changes. Click here to see the full project data catalogue. In our pipeline definition where simply construct the output with the matching name from the data catalogue and the saving is dealt with for us.
kedro-viz is a small plugin that helps us visualise the resulting pipelines.
The pipelines in our project look like this:
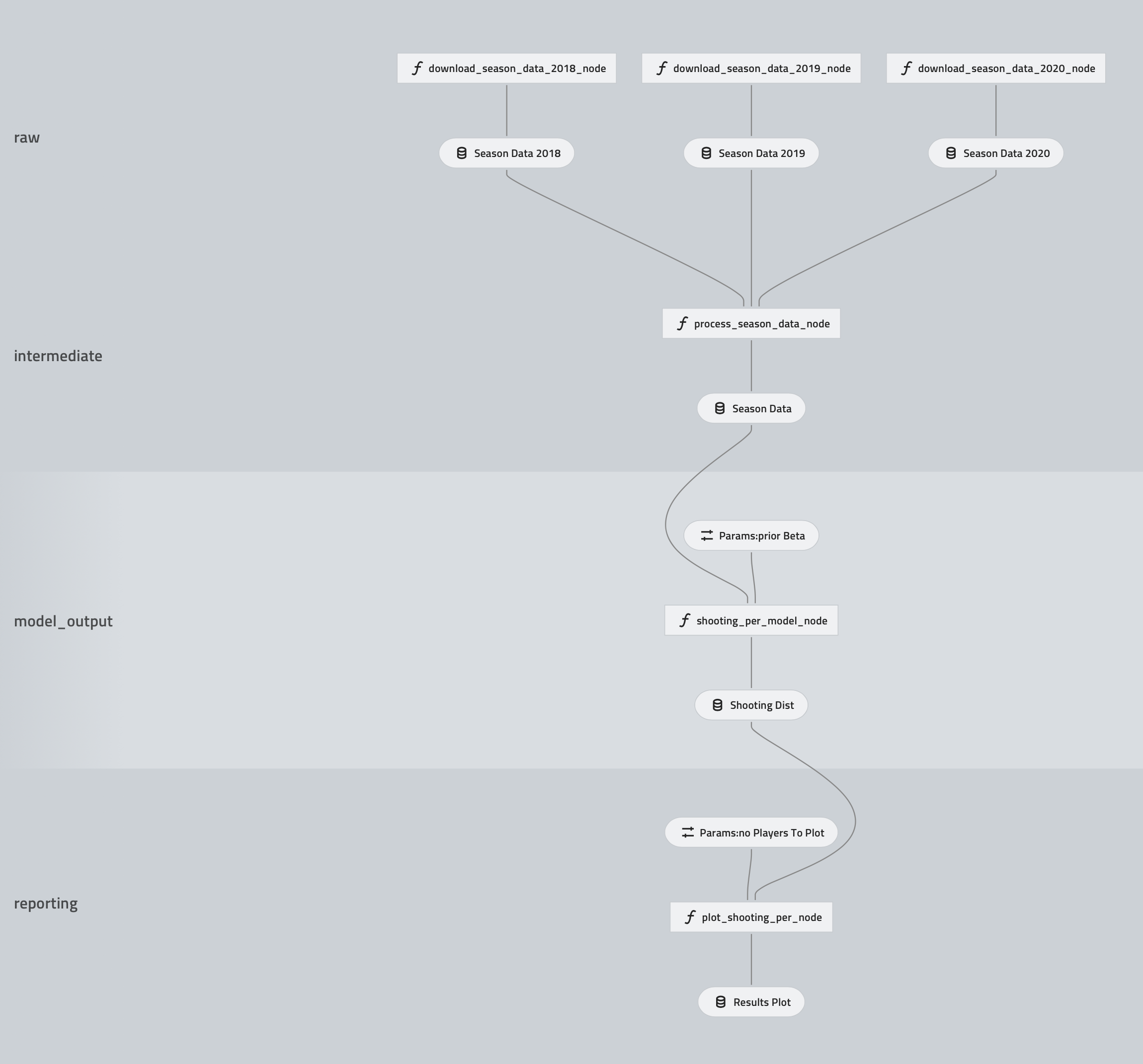
The raw and intermediate layers are used within the data engineering pipeline. The model output and reporting layers are within the data science pipeline.
After constructing the pipelines we can run the entire project with kedro run.
And after each run we can an image of our results as follows:
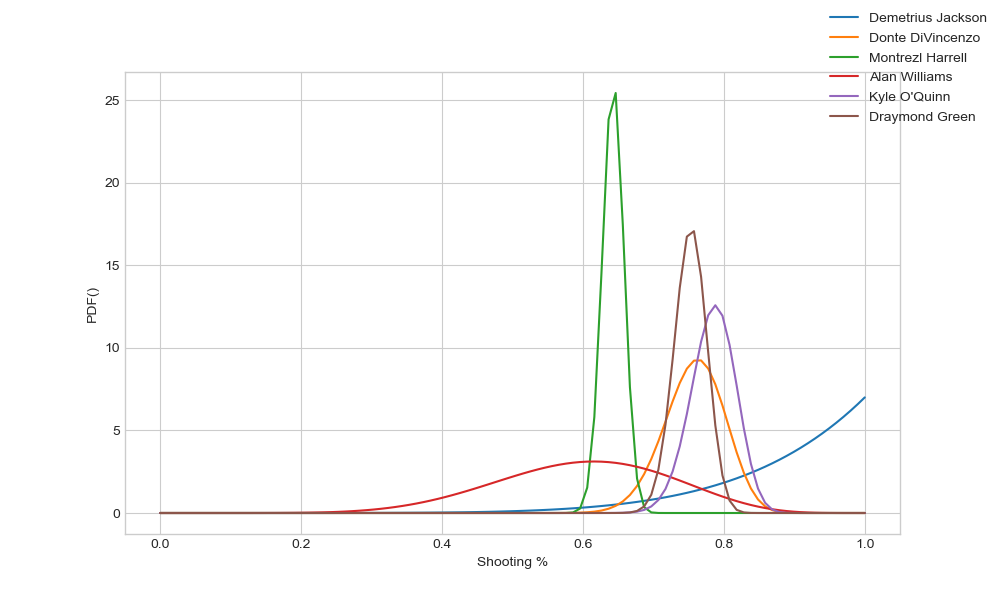
When we need to production there are various routes, including creating a docker image which can be run elsewhere.
There is also some integration with spark for big data tasks.
The project framework was fairly easy to work with. Compared with other DAG based pipeline tools this was one of the easier ones. It has less boilerplate required compared to pipelines from AzureML or Kubeflow. However they are offering different feature sets. For example AzureML has more features around experimentation tracking, more comprehensive dataset tracking and pipeline caching. Kedro has some plugins available to build more features on top, for example there is some integration with MLFlow for experiment tracking.
There is definitely more to explore, but so far it’s quite interesting. Kedro seems fairly well suited to smaller data analysis projects and as such I will consider using Kedro as a basis for future projects.